Interface Design in Canorus: Reducing Modes
- 8 minutes read - 1703 wordsDue to the complexities of music notation, music software has a tendency to have many modes. Notation software may have a separate mode (tool) for note entry, title text, lyric text, slurs, expressions, accents, etc. Compare this to handwritten notation which uses one tool for all these elements: a pencil. Understandably notation software can be daunting or frustrating for even the seasoned musician or composer. Due to the complexity of music notation and the limitations of the computer interface, it is not possible to achieve an entirely modeless design. Even when composing by hand most people will encounter at least two modes: writing (with pen or pencil) and playback (usually piano).
However, the notation editor Canorus should strive to minimize unnecessary modalism by reducing the number of modes and reducing the barriers between these modes.
Status of Canorus interface
A strength of Canorus is its current avoidance of dialog boxes. Dialog boxes are often bad design choices because they interrupt the workflow of the user and are modal in nature. The user is forced to complete (or cancel) the dialogue before he/she can do anything else.
That said, dialog boxes are not always the wrong design choice. For example, Canorus uses dialog boxes for Save As, Import, Export, and Open. The complexity of file navigation would add extensive clutter to the main interface which is not directly related to notation editing. More importantly a non-modal Open and Save As would break the native look and feel of the application.
Despite the intentional avoidance of dialog boxes in Canorus, the interface is very mode heavy in other ways. To be clear modes are sometimes necessary, but there are several ways Canorus can reduce the modal nature of its interface. Doing so can simplify the display layout, reduce user mode errors, and avoid interrupting the user workflow.
Slurs vs. ties: unnecessary modalism
Many notation programs distinguish between slurs and ties and have separate tools for each. This makes sense from a programming perspective since slurs and ties have different meanings and interpretations during playback. However musicians would not immediately think of these as separate notations, nor need the computer interface. The meaning is unambiguous from the context:
- A tie occurs between two identical pitches and implies no break between the notes during playback
- A slur occurs between two different pitches or between three or more notes regardless of pitch and implies a slur or phrase marking.
The separation of slurs and ties into two separate tools causes confusion and mode errors for newbies regardless of musical training. I have witnessed this confusion when introducing people to music notation on the computer, and I have even received printed music parts where ties and slurs have been confused.
If a user inserts a tie and the next note is a different pitch, the user obviously intended to insert a slur, yet most notation software will insert a perfectly horizontal tie that does not line up with the next note. Why should the software be so pedantic? Also important is the ability to select and drag a tie to a different group of notes regardless of whether it would become a tie or a slur.
Multi-voicing with modes
Support for multiple voices is generally modal in notation software: each voice has a separate mode. Unless a user is taught how to use multi-voicing modes or decides to look it up, he/she is unlikely to discover them and (incorrectly) assume the software is incapable of producing the desired notation.
Modal multi-voicing lends itself well to chorales or fugues where up-stems and down-stems correspond with voice 1 (black notes) and voice 2 (red notes) throughout the piece (see figure 1 below).
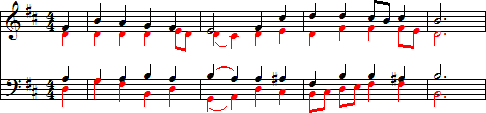
Figure 1
Notice up-stems correspond with soprano and tenor voices throughout piece. Down-stems correspond with alto and bass voices.
On the other hand, the modal “multi-voicing” approach is less suited to other types of notation where the connection between stem direction and voicing is not as strong. For example hymnals often use a mixture of chords and multi-voicing to save space and avoid collisions between lyrics and down-stems (see figure 2 below).
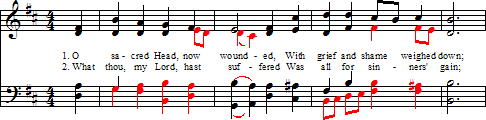
Figure 2
A mixture of chords and multi-voicing is common in keyboard music and vocal music with lyrics. Notice multi-voicing is used where note durations differ between soprano and alto or tenor and bass. Notes of the same duration are typically written as chords.
I often find myself needing this type of notation and find the modal approach frustrating. Switching voice modes regularly to enter chords can be tedious. Also the process of inserting hidden “placeholder” rests for non-modal beats within a measure further complicates multi-voicing.
Non-modal multi-voicing
I think it would be interesting if you could select note heads from within a chord and flip the stem direction of those notes independently from the rest of the chord (see figure 3 below).
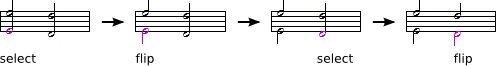
Figure 3
A non-modal method of moving notes to a second voice. Instructions: select note head with mouse, flip stem via screen button or keyboard shortcut.
This method is ideal for editing voicing after the notes have already been entered. Notice that the user need not worry about entering hidden placeholder rests, the software would do this automatically. Some notation software changes stem directions throughout a measure (often undesirably) whenever a new voice is added. In this scenario the software would change stem directions for the selected notes only.
Noteworthy Composer allows notes of different durations to be placed above or below an existing note in the same way that one would enter a new note to a chord. Stem directions are flipped automatically to accommodate the addition. This method lends itself well to the mixed notation mentioned above where multi-voicing is only used for chords containing different note durations. This behavior could be enabled by default or perhaps via a quasimode which only allows multi-voicing while holding a modifier key (such as command or control).
The two implementations described above are limited to interactions with the mouse and computer keyboard. A possible MIDI keyboard implementation would mimic the way multi-voicing is performed on a keyboard instrument. If new notes are entered while another note is held the notation is converted to multi-voicing (see figure 4 below).
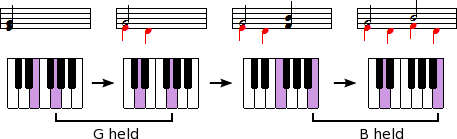
Figure 4
A non-modal method of multi-voicing with MIDI keyboard. This could be step-time or real-time entry.
Since all voices are entered at once, this is far faster than entering voices one at a time. Since it mimics performance it is simpler to understand and non-modal. A limitation is where notation differs from actual keyboard performance. For example, a multi-voice unison is performed identically to a single-voice unison (see figure 5 below).

Figure 5
Instances where keyboard performance of multi-voicing is indistinguishable from single-voicing.
Perhaps there are ways to overcome this limitation such as a way to convert a single-voice unison to a multi-voice unison via keyboard shortcut or a means to specify that at least two voices are required throughout the staff.
It may be too early to entirely abandon modal interfaces for multi-voicing, but careful thought in this area could reap many benefits for the user. If modal multi-voicing is employed, mode states should be clearly visible (e.g. grey out all non-active voices).
“Don’t make me leave note entry”
Note entry should be where the user spends most of their time (with the possible exception of the lyric tool for songs with many lyrics). Since Canorus uses LilyPond for final rendering most formatting issues will be dealt with automatically and probably not require significant manual adjustments.
However anyone who has entered music into the computer using notation software has probably encountered other interruptions and time investments: “Shall I interrupt note entry to insert dynamics/accents/slurs/etc. while I’m thinking of them or should I wait till the end?” The first option usually requires switching modes (interrupting the user work flow) and if many mode switches are required it probably takes a little longer. The second option requires the user to remember all the dynamics/accents/slurs/etc. that he or she wishes to insert. The user is likely to miss some markings that he or she originally intended.
A musician working with pencil and paper may go back through a piece to add or revise their markings but will probably include most of them at the time of “note entry.” The modal interface imposes artificial obstructions on the user.
Using keyboard shortcuts to switch between modes rather than requiring mouse movements reduces the barriers between modes. Better yet are shortcuts that access frequent markings directly. All the most common markings should be accessible via keyboard shortcuts. The table below lists some markings along with possible shortcuts.
| Marking | Keyboard shortcut |
|---|---|
| ff | ff |
| f | f |
| mf | m or mf |
| mp | mm or mp |
| p | p |
| pp | pp |
| < [hairpin crescendo] | < |
| > [hairpin diminuendo] | > |
| . [staccato] | s or ' [apostrophe] |
| _ [legato marking] | l or - [hyphen] |
| > [accent] | a |
| v [hat accent] | v |
| [tie] | = [equals] or _ [underscore] |
| [slur] | ( [left parenthesis] for starting note slur) [right parenthesis] for ending note slur |
| tr. | r or ~ [tilde] |
| expression text [e.g. cantabile, etc.] | t for starting text entry [enter/return] for ending text entry (ideally expression text has auto-complete) |
In addition to these markings there are other things that should be possible without leaving note entry such as flipping ties/slurs above or below notes, flipping stem directions for individual notes, converting/entering grace notes, breaking/joining eight-note beams, etc.
Conclusion
I recognize that it may be some time before these suggestions can be implemented. My intention is to start a discussion about usability in notation software and lay a strong foundation for interface design in Canorus.
Since Canorus is still in its early development stages, it does not carry a legacy of poor design choices or a large user base who have become used to a particular design choice. Canorus has the opportunity to carefully plan and design its interface from the start to address usability issues. Canorus is not driven by a need to return profit from flashy upgrades and (poorly implemented) feature bloat. Therefore Canorus can afford to address one of the most important needs of the user: usability. Thinking of ways to reduce modalism will bring us a long way.